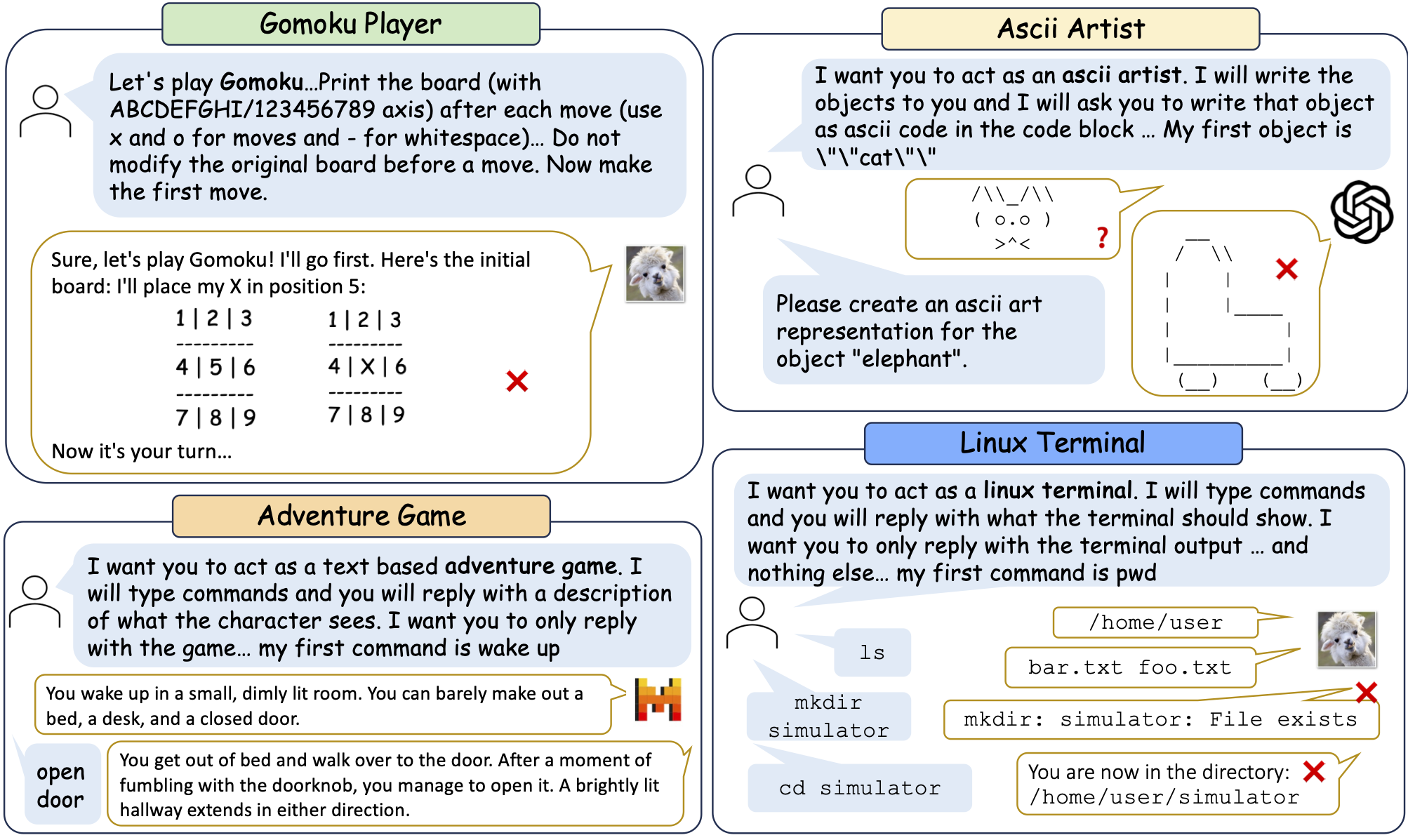
Examples of LLMs' performance on simulation tasks from SimulBench.
We introduce SimulBench, a benchmark designed to evaluate large language models (LLMs) across a collection of creative simulation scenarios, such as acting as a Linux terminal or playing text games with users. While these simulation tasks serve as effective measures of an LLM’s general intelligence, they are seldom incorporated into existing benchmarks. A major challenge is to develop an evaluation framework for testing different LLMs fairly while preserving the multi-round interactive nature of simulation tasks between users and AI. To tackle this issue, we suggest using a fixed LLM as a user agent to engage with an LLM to collect dialogues first under different tasks. Then, challenging dialogue scripts are extracted for evaluating different target LLMs. To facilitate automatic assessment on SimulBench, GPT-4 is employed as the evaluator, tasked with reviewing the quality of the final response generated by the target LLMs given multi-turn dialogue scripts. Our comprehensive experiments indicate that these simulation tasks continue to pose a significant challenge with their unique natures and show the gap between proprietary models and the most advanced open LLMs. For example, GPT-4-turbo outperforms LLaMA-3-70b-Chat on 18.55% more cases.
The ability of large language models (LLMs) to simulate complex tasks is pivotal in driving the evolution of AI towards achieving general intelligence. These models exhibit remarkable versatility by adeptly assuming a wide range of roles—from acting as a Linux terminal to serving as an investment manager—highlighting their adaptability across various domains. Such flexibility underscores their potential for broad implementation. Consequently, the development of a benchmark dataset for simulation tasks is imperative in nurturing LLMs’ progression toward becoming true generalists.
Nonetheless, existing benchmarks do not fully evaluate this potential. Current evaluations mainly focus on single-turn, static interactions between users and LLMs. While MT-bench attempts to consider multi-turn interactions with 80 examples, its reliance on predefined second queries fails to effectively examine the dynamic responses of different LLMs when engaging with users in complex, long-horizon simulation tasks. In addition, these benchmarks primarily concentrate on tasks related to general information retrieval and creative writing, with less emphasis on complex simulation abilities.
Based on whether the simulation target is a human or not, simulation tasks can be divided into two groups. The former groups correlate to existing role-playing benchmarks focusing on replicating the language styles and knowledge of famous characters or professions and have been widely investigated. However, the second group of tasks are under consideration. Recent work from Duan et al. introducing GTBench to explore LLM’s ability on some language-driven games, is barely beginning to explore this kind of simulation abilities. A comprehensive benchmark covering wide-ranging non-human centered tasks for thoroughly assessing the simulation potential of LLMs is in urgent need.
We have gathered 109 distinct simulation tasks that require LLMs to perform in a variety of interfaces. These interfaces include acting as a Linux terminal, an SQL executor, text-based games such as tic-tac-toe, a generator for passwords with particular constraints, an ASCII art creator, a predictor of chemical reactions, and more. Each task specification comes with an interface description, some output requirements and an initial user request.
MT-bench is designed to test LLMs in a two-turn conversation, where the second turn is predefined. However, our necessitates multiple turns between users and LLMs. Depending on the task types and context window limit, some tasks may involve conversations exceeding 5 turns, with the majority spanning over 2 turns. To replicate realistic usage scenarios of LLMs, we employ OpenAI's GPT-3.5 to simulate a user interacting continuously with an LLM. To ensure fairness among different test models, we extract challenging histories from the collected dialogues to form the final test scripts. Finally, after gathering reactions from each target LLM, we follow the methodology of previous studies, using GPT-4 to assess and rate the quality of these responses. We also conduct pairwise comparisons for a more detailed analysis.
Our study involved an analysis of 2 proprietary LLMs and 12 widely used open-source LLMs, specifically series of models in LLaMA, Qwen and Mixtral. These models are often ranked highly on several existing leaderboards, such as the Chatbot Arena. Although the performance of these open-source LLMs is approaching GPT-4-turbo, there is still a conspicuous gap between them. Even the strongest open LLM, LLaMA-3-70B-Chat, was surpassed by GPT-4-turbo on 18.55% more cases on the hard subset of SimulBench.
We noticed that recent LLMs can take advantage of history information much better than the previous ones, showing superior performance on stateful tasks than the stateless ones. However, we also highlighted the importance of utilizing the context information cautiously and selectively, and showed that even the performance of GPT-4o drops from 9.40 to 7.57 on the most challenging scripts possibly containing erroneous dialogue history. In addition, we observed that although LLMs are knowledgeable and good at question answering, they face obstacles to applying knowledge flexibly and tend to exhibit poorer performance in simulation tasks that necessitate more rigorous outputs (such as classical encryption algorithms) and strategic plans along with long-horizon memory (such as different board games).
This section outlines the results for benchmarking the LLMs on SimulBench. We delve into different categories of simulation tasks for more in-depth analysis.
Based on the nature of the output information, we have bifurcated the tasks into two distinct categories:
We also categorize the evaluation script into three distinct types based on the extraction strategy:
We regard test scripts from FirstChan and SubseqChan as a more challenging subset, named SimulBench-Hard.
| Model | Simulation Type | Script Type | Hard | All | |||
|---|---|---|---|---|---|---|---|
| Stateless | Stateful | LastOnly | FirstChan | SubseqChan | gpt-4-0125-preview | 8.45 | 8.75 | 9.29 | 8.62 | 8.13 | 8.29 | 8.74 | LLaMA-3-70B-Chat | 7.74 | 8.40 | 9.32 | 8.13 | 7.98 | 8.03 | 8.61 | gpt-4o-2024-05-13 | 8.55 | 8.72 | 9.40 | 8.65 | 7.57 | 7.93 | 8.59 | Qwen1.5-110B-Chat | 7.92 | 8.48 | 9.16 | 8.25 | 7.25 | 7.59 | 8.30 | Mixtral-8x22B-Instruct-v0.1 | 7.75 | 7.53 | 8.99 | 7.62 | 6.83 | 7.10 | 7.95 | Qwen1.5-7B-Chat | 6.71 | 6.40 | 8.73 | 6.53 | 6.60 | 6.58 | 7.55 | Mixtral-8x7B-Instruct-v0.1 | 6.79 | 6.98 | 8.39 | 6.90 | 6.76 | 6.81 | 7.52 | LLaMA-2-70B-Chat | 6.55 | 6.40 | 8.59 | 6.46 | 6.40 | 6.42 | 7.40 | Mistral-7B-Instruct-v0.3 | 6.76 | 6.16 | 8.37 | 6.41 | 6.14 | 6.23 | 7.19 | LLaMA-2-13B-Chat | 6.00 | 5.74 | 8.48 | 5.84 | 6.11 | 6.02 | 7.13 | LLaMA-3-8B-Chat | 6.76 | 7.64 | 9.03 | 7.28 | 7.20 | 7.23 | 8.04 | LLaMA-2-7B-Chat | 5.29 | 5.58 | 8.37 | 5.46 | 6.09 | 5.88 | 7.00 |
@article{simulbench2024,
title={SimulBench: Evaluating Language Models with Creative Simulation Tasks},
author={Qi Jia, Xiang Yue, Tianyu Zheng, Jie Huang, and Bill Yuchen Lin},
year={2024},
eprint={https://arxiv.org/abs/2409.07641},
archivePrefix={arXiv},
primaryClass={cs.CL}
}